
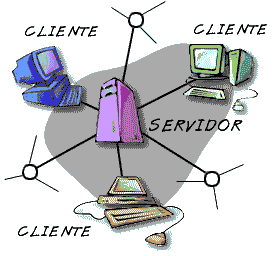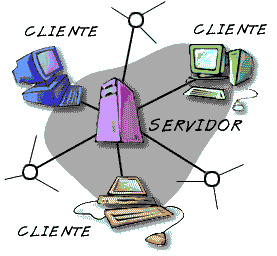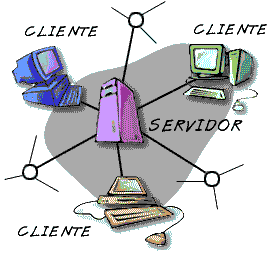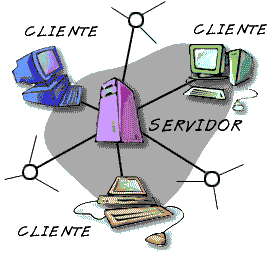
Esta arquitectura consiste básicamente en que un programa, el Cliente informático realiza peticiones a otro programa, el servidor, que les da respuesta.
Aunque esta idea se puede aplicar a programas que se ejecutan sobre una sola computadora es más ventajosa en un sistema multiusuario distribuido a través de una red de computadoras.
En esta arquitectura la capacidad de proceso está repartida entre los clientes y los servidores, aunque son más importantes las ventajas de tipo organizativo debidas a la centralización de la gestión de la información y la separación de responsabilidades, lo que facilita y clarifica el diseño del sistema.
La separación entre cliente y servidor es una separación de tipo lógico, donde el servidor no se ejecuta necesariamente sobre una sola máquina ni es necesariamente un sólo programa.
Una disposición muy común son los sistemas multicapa en los que el servidor se descompone en diferentes programas que pueden ser ejecutados por diferentes computadoras aumentando así el grado de distribución del sistema.
La arquitectura cliente-servidor sustituye a la arquitectura monolítica en la que no hay distribución, tanto a nivel físico como a nivel lógico.
Ventajas de la arquitectura cliente-servidor:
Centralización del control: los accesos, recursos y la integridad de los datos son controlados por el servidor de forma que un programa cliente defectuoso o no autorizado no pueda dañar el sistema.
Escalabilidad: se puede aumentar la capacidad de clientes y servidores por separado.
Se reduce el tráfico de red considerablemente. Idealmente, el cliente se comunica con el servidor utilizando un protocolo de alto nivel de abstracción como por ejemplo SQL (Structured Query Language), que es un lenguaje declarativo de acceso a bases de datos relacionales que permite especificar diversos tipos de operaciones sobre las mismas. Aún características del álgebra y el cálculo relacional permitiendo lanzar consultas con el fin de recuperar información de interés de una base de datos, de una forma sencilla. Es un lenguaje de cuarta generación (4GL)
El servidor de cliente es la arquitectura de red que separa al cliente (a menudo un uso que utiliza un interfaz utilizador gráfico) de un servidor. Cada caso del software del cliente puede enviar peticiones a un servidor. Los tipos específicos de servidores incluyen los servidores de la tela, los servidores del uso, los servidores de archivo, los servidores terminales, y los servidores del correo. Mientras que sus propósitos varían algo, la arquitectura básica sigue siendo igual.
Aunque esta idea se aplica en una variedad de maneras, en muchas diversas clases de usos, el ejemplo más fácil de visualizar es el uso actual de Web pages en el Internet.
Características de un Servidor.
Voz pasiva (esclavo).
Esperas para las peticiones.
Sobre el recibo de peticiones, las procesa y entonces los servicios contestaron.
Características de un Cliente.
Activo (amo).
Envía peticiones.
Las esperas para y reciben contestaciones del servidor.
Los servidores pueden ser apátridas o stateful. Un servidor apátrida no guarda ninguna información entre las peticiones. Un servidor stateful puede recordar la información entre las peticiones. El alcance de esta información puede ser global o sesión-específico. Un servidor del HTTP para las páginas estáticas del HTML es un ejemplo de un servidor apátrida mientras que Apache Tomcat es un ejemplo de un servidor stateful.
La interacción entre el cliente y el servidor se describe a menudo usando diagramas de secuencia. Los diagramas de secuencia se estandardizan en el UML.
Otro tipo de arquitectura de red se conoce como arquitectura del par-a-par porque cada nodo o caso del programa es un “cliente” y un “servidor” y cada uno tiene responsabilidades equivalentes. Ambas arquitecturas están en uso amplio.
Arquitectura con gradas
Una arquitectura genérica del cliente/servidor tiene dos tipos de nodos en la red: clientes y servidores. Consecuentemente, estas arquitecturas genéricas se refieren a veces como arquitecturas “de dos niveles”.
Algunas redes consistirán en tres diversas clases de nodos: cliente, servidores del uso que datos de proceso para los clientes, y servidores de la base de datos que almacenan los datos para los servidores del uso. Esta configuración se llama una arquitectura de la tres-grada.
La ventaja de una arquitectura de la n-grada comparado con una arquitectura de dos niveles (o una tres-grada con un de dos niveles) es que separa hacia fuera el proceso eso ocurre para mejorar el balance la carga en los diversos servidores; es más escalable. Las desventajas de las arquitecturas de la n-grada son: 1.-Pone más carga en la red 2.-Es mucho más difícil programar y probar software que en arquitectura de dos niveles porque más dispositivos tienen que comunicarse para terminar la transacción de un usuario.
Ventajas
Algunas de las ventajas del ambiente cliente/servidor son:
Todos los datos se almacenan en los servidores, así que tienen capacidad mejor del control de la seguridad. El servidor puede controlar el acceso y el recurso al cerciorarse que dejó solamente ésos accesos de usuarios permitidos y cambia datos.
Es más flexible que el paradigma del P2P para poner al día los datos u otros recursos.
Hay las tecnologías maduradas diseñadas para el paradigma de C/S que asegura seguridad, el usuario-friendliness del interfaz, y la facilidad de empleo.
Cualquier elemento de la red C/S puede ser aumentado fácilmente.
Desventajas
Algunas de las desventajas del ambiente cliente/servidor son:
La congestión del tráfico ha sido siempre un problema desde el primer día del nacimiento del paradigma de C/S. Cuando una gran cantidad de clientes envían peticiones al mismo servidor al mismo tiempo, puede ser que cause muchos de los apuros para el servidor. Más clientes hay más apuros que tiene. Mientras que, la anchura de banda de la red del P2P se compone de cada nodo en la red, cuanto más nodos hay, mejor la anchura de banda que tiene.
El paradigma de C/S no tiene la buena robustez como red del P2P. Cuando el servidor está abajo, las peticiones de los clientes no pueden ser satisfechas. En la mayor parte de redes del P2P, los recursos están situados generalmente en nodos por todas partes de la red. Aunque algún nodos salen o abandonan descargar; otros nodos pueden todavía acabar de descargar consiguiendo datos del resto de los nodos en la red.
El software y el hardware de un servidor es generalmente muy terminantes. Un hardware regular del ordenador personal puede no poder servir sobre cierta cantidad de clientes. Mientras tanto, una edición casera de Windows XP incluso no tiene IIS a trabajar como servidor. Necesita software y el hardware específico satisfacer el trabajo. Por supuesto, aumentará el coste.
Dirección
Los métodos de dirección en ambientes del servidor de cliente se pueden describir como sigue:
Dirección del proceso de la máquina; donde la dirección se divide como sigue process@machine. Por lo tanto 56@453 indicaría el proceso 56 en la computadora 453.
Servidor de nombres; Los servidores de nombres tienen un índice de todos los nombres y direcciones de servidores en el dominio relevante.
Localización de Paquetes; Los mensajes de difusión se envían a todas las computadoras en el sistema distribuido para determinar la dirección de la computadora de la destinación.
Comerciante; Un comerciante es un sistema que pone en un índice todos los servicios disponibles en un sistema distribuido. Una computadora que requiere un servicio particular comprobará con el servicio que negocia para saber si hay la dirección de una computadora que proporciona tal servicio.
